Część Teoretyczna
Moduł 2: Wprowadzenie do LVM - teoria
Czas Trwania: 7 minut
2. Wprowadzenie do LVM: co to jest, podstawowe zastosowania.
Konfiguracja LVM i RAID
LVM (Logical Volume Manager) - Menadżer woluminów logicznych jest nową technologią pozwalającą wykorzystać miejsce na kilku napędach jako jeden logiczny wolumin.
Daje to możliwość elastycznego przydzielania dostępnej przestrzeni dyskowej dla aplikacji i użytkowników.
Po stworzeniu logicznych woluminów za pomocą LVM - można (z pewnymi ograniczeniami) zmieniać rozmiar i przenosić logiczne woluminy nawet w czasie ich pracy (mogą być zamontowane i normalnie używane).
Możemy również wykorzystać LVM do zarządzania woluminami logicznymi z nazwami które są sensowne z punktu widzenia użytkownika (np. Marketing, Handel), zamiast fizycznych nazw dysków.
Aby dobrze skonfigurować system plików za pomocą LVM, musimy poznać następujące zagadnienia:
- Jak używać komponentów LVM
- Jak wykorzystać cechy LVM
- Konfiguracja logicznych woluminów za pomocą YaSTa
- Konfiguracja LVM z linii poleceń
Dodatkowe informacje o konfigurowaniu LVM można znaleźć w LVM HOWTO:
Jak używać komponentów LVM
W linuksowym systemie plików konwencjonalne partycje na dysku twardym są mało elastyczne.
Gdy partycja jest zapełniona, musimy przenieść dane na inne medium zanim możemy zwiększyć rozmiar partycji, po zmianie rozmiaru - musimy stworzyć nowy system plików, a następnie ponownie przekopiować dane.
W dodatku - na ogół te zmiany łączą się ze zmianami partycji sąsiednich, co znowu zmusza do robienia kopii zapasowych tych partycji na inne media, a następnie, po zakończeniu partycjonowania, na nowo zapisania oryginalnych danych.
Projekt LVM był odpowiedzią na problem modyfikacji rozmiaru partycji w linuksowych systemach plików.
LVM dostarczą dodatkowej warstwy abstrakcji - wirtualnego zasobu pamięci zwanego grupą woluminów, z których z kolei można tworzyć potrzebne woluminy.
System operacyjny zapewnia dostęp do logicznych woluminów identycznie jak do fizycznych partycji.
To podejście pozwala na zmianę rozmiaru fizycznych mediów bez wpływu na aplikacje.
Podstawowa struktura LVM składa się z następujących składowych:
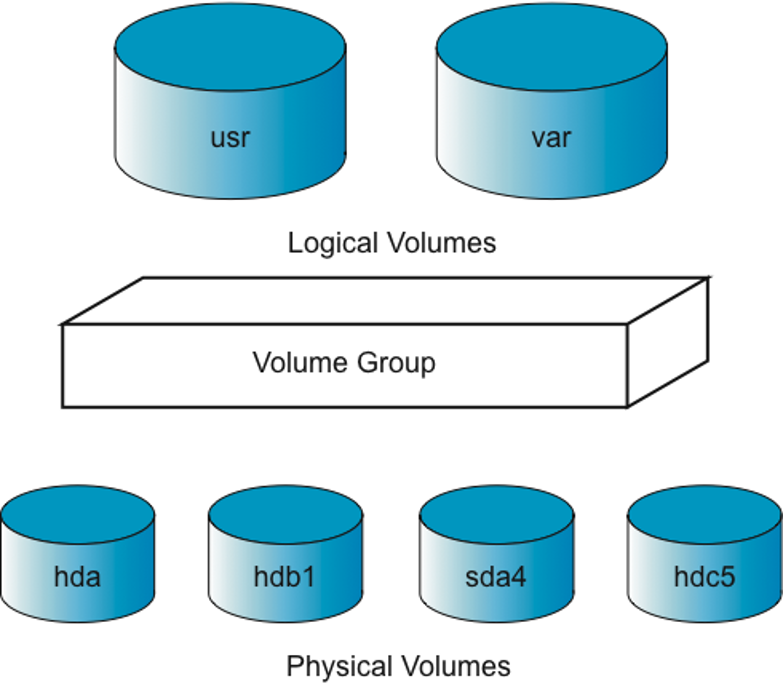
Jak używać komponentów LVM
- Fizyczny wolumin – fizycznym woluminem może być partycja lub cały dysk.
- Grupa woluminów – grupa woluminów zawierająca jeden lub wiele fizycznych woluminów zgrupowanych razem.
Fizyczne partycje mogą się rozpościerać na różnych dyskach twardych. Można dodać dyski twarde lub partycje do grupy woluminów w dowolnym momencie, kiedy tylko jest to potrzebne.
Grupy woluminów można również redukować (zmniejszać ich wielkość) poprzez usunięcie fizycznych woluminów (dysków twardych lub partycji).
- Logiczne woluminy – są częścią grupy woluminów. Logiczne woluminy można formatować lub montować tak jak fizyczne partycje.
Można myśleć o grupie woluminów jako o dyskach twardych, a o logicznych woluminach jak o partycjach na tych dyskach.
Grupę woluminów można podzielić na szereg logicznych dysków, którym można przypisać nazwy urządzeń (np. /dev/system/usr) podobnie jak konwencjonalnym partycjom (/dev/hda1).
Jak wykorzystać cechy LVM
LVM jako bardzo elastyczne i wygodne rozwiązanie przy wprowadzaniu zmian w organizacji przestrzeni dyskowej jest bardzo użyteczne praktycznie dla dowolnego komputera.
Następujące cechy LVM są szczególne użyteczne przy praktycznej implementacji rozwiązań organizacji pamięci masowej:
- można połączyć kilka dysków twardych lub partycji w dużą grupę woluminów,
- wygodna zmiana organizacji pamięci masowej - w każdej chwili można powiększyć logiczny wolumin, gdy brakuje na nim wolnego miejsca dla danych.
Zmiana rozmiarów logicznych woluminów jest o wiele łatwiejsza niż zmiana rozmiarów partycji fizycznych.
- Możemy utworzyć ekstremalnie duże logiczne woluminy – liczone w terabajtach,
- zdolność do wymiany części sprzętu bez wyłączania całości ( “hot-swappable”) - można dodawać dysk twardy do grupy woluminów przy pracującym systemie,
- można “na gorąco” dodać logiczny wolumin w pracującego systemie - o ile jest wolna przestrzeń w grupie woluminów,
- można użyć kilka dysków z poprawioną wydajnością w trybie RAID 0 (striping),
- nie ma praktycznie limitu liczby logicznych woluminów (limit w LVM v1 wynosił 256),
- dostępna jest cecha tzw. migawek (snapshot) z systemu i co za tym idzie, - tworzenia kopii zapasowych w pracującym systemie - " na bieżąco".
Konfiguracja LVM z linii poleceń
Procedura “ręcznej” konfiguracji LVM poleceniami liniowymi zawiera wiele kroków, z dedykowanymi narzędziami dla każdego z nich:
- Narzędzia do administracji fizycznymi woluminami
- Narzędzia do zarządzania grupami woluminów
- Narzędzia do administracji woluminami logicznymi
J
est to krótki przegląd, niezawierający wszystkich narzędzi LVM.
Do przejrzenia narzędzi dostępnych z LVM, należy wprowadzić polecenie
|
|
Wyświetlone zostaną odpowiednie strony manuala.
Narzędzia do administracji fizycznymi woluminami
Partycje lub dyski - LVM może obsługiwać jako fizyczne woluminy.
ID partycji użytej jako część LVM powinien być Linux LVM, 0x8e; ale 0x83, Linux też jest obsługiwany poprawnie.
By wykorzystać cały dysk jako fizyczny wolumin - nie może zawierać on tablicy partycji.
Istniejącą tablicę partycji nadpisujemy poleceniem liniowym dd:
|
|
Następnym krokiem będzie inicjalizacja partycji LVM narzędziem pvcerate:
|
|
Pozostałe polecenia:
|
|
Narzędzia do zarządzania grupami woluminów
Narzędzie vgcreate wykorzystywane jest do tworzenia nowych grup woluminów.
Poniższy przykład pokazuje tworzenie grupy woluminów o nazwie system z dodaniem partycji /dev/sdb1:
|
|
Pozostałe polecenia:
vgs, vgdisplay, vgresize, vgreduce, vgextend, vgchange, vgscan
Narzędzia do administracji woluminami logicznymi
W celu stworzenia woluminu logicznego podajemy polecenie lvcreate określając rozmiar woluminu, nazwę woluminu i grupy woluminów, w ramach której wolumin logiczny tworzymy. W tym przypadku rozmiar woluminu to 100 MB.
Możemy też przypisać całą dostępną przestrzeń poniższym poleceniem:
|
|
Pozostałe polecenia:
|
|
lvs, lvdisplay, lvresize, lvreduce, lvextend
Narzędzia do zmiany rozmiarów partycji
W celu zmiany rozmiaru partycji możemy zastosować poniższe narzędzia:
- xfs_growfs - rozszerza istniejący system plików XFS
|
|
- resize2fs - zmienia rozmiar systemu plików ext2/ext3/ext4
|
|
Zarządzanie programowym RAID
Skrót RAID pochodzi od Redundant Array of Inexpensive Disks, czyli: nadmiarowa macierz tanich dysków.
RAID (Redundant Array of Independent Disks) to technologia wirtualizacji przechowywania danych, która łączy wiele fizycznych komponentów dysków twardych w jedną lub więcej logicznych jednostek w celu zapewnienia redundancji danych, poprawy wydajności lub obojga. Poniżej szczegółowo opiszę poziomy RAID 0, 1, 5, 6, 50, 60 i 1E, skupiając się na ich kluczowych cechach, korzyściach i przypadkach użycia.
Celem RAID - scalenie wielu partycji dysku w jeden duży wirtualny dysk twardy, aby zoptymalizować wydajność i poprawić bezpieczeństwo danych.
Rozróżniamy dwa typy macierzy RAID:
sprzętową– dyski twarde są podpięte do oddzielnego kontrolera sprzętowego RAID. System operacyjny widzi połączone dyski twarde jako jedno urządzenie, nie ma potrzeby konfigurowania tego typu macierzy z poziomu systemu operacyjnego.programową– dyski twarde są łączone w macierz przez system operacyjny. System operacyjny widzi każdy dysk osobno, więc należy odpowiednio go skonfigurować by mógł te dyski traktować jako macierz RAID.
W przeszłości macierz sprzętowa zapewniała lepszą wydajność systemu i bezpieczeństwo danych.
Obecnie, przy dojrzałości rozwiązań programowego RAID w jądrze Linuksa, macierze programowe nie odbiegają osiągami i bezpieczeństwem od macierzy sprzętowych.
Dyski można łączyć w różne typy macierzy RAID.
Najczęściej w praktyce używamy następujących typów macierzy:
RAID 0 - Stripping
RAID 0(striping) - paskowy; inaczej nazywamy to rozproszeniem. Jest konfiguracją, która właściwie nie zasługuje na określanie jej w kategoriach RAID ponieważ w trybie tym nie występuje redundancja (nadmiarowość), nie kładzie się też zupełnie nacisku na bezpieczeństwo danych.
Dane są zapisywane na kilku połączonych w macierz dyskach (blokami), co znacznie przyspiesza proces zapisu. Dane zapisywane są i odczytywane na wszystkich dyskach za pomocą specjalnego algorytmu rozdzielającego. Dzięki temu uzyskuje się najwyższą możliwą wydajność, jednak ryzyko awarii zwiększa się wraz z ilością użytych dysków twardych. Jeśli jeden z nich ulegnie uszkodzeniu, wszystkie dane w macierzy ulegają destrukcji.
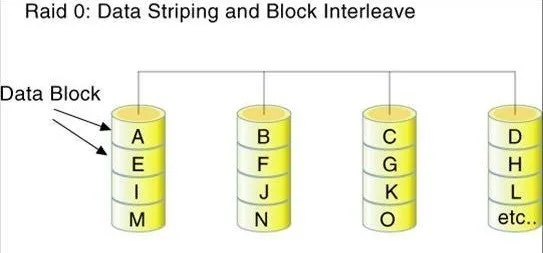
- Opis:
RAID 0równomiernie rozdziela dane na dwóch lub więcej dyskach bez redundancji. Zwiększa to wydajność, ponieważ umożliwia równoległe odczyty i zapisy na wielu dyskach. - Korzyści: Maksymalizacja wydajności; wyższa przepustowość.
- Wady: Brak redundancji; jeśli jeden dysk ulegnie awarii, wszystkie dane w tablicy zostaną utracone.
- Przypadki użycia: Sytuacje, w których wydajność jest priorytetem nad niezawodnością danych, takie jak buforowanie.
RAID 1 - Mirroring
RAID 1 (mirroring) - lustrzane odbicie dwóch dysków lub ich partycji fizycznych, jest przeciwieństwem macierzy RAID 0: oferuje bezpieczeństwo kosztem nadmiarowości sprzętu. Te same dane są zapisywane równolegle na dwóch dyskach (dyski stanowią swoje jako lustrzane odbicie).
W przypadku, gdy jeden z dysków ulegnie awarii, wszystkie zadania przejmuje drugi dysk.
Dużą wadą trybu RAID 1 jest to, iż z całkowitej pojemności dysków dostępna jest dokładnie jej połowa.
Możliwe są także konfiguracje z więcej, niż tylko jednym lustrem, jednak wtedy pojemności są odpowiednio mniejsze.
Dobre implementacje RAID 1 pozwalają na jednoczesny odczyt danych z obu dysków, więc przynajmniej szybkość odczytu jest większa, niż przy użyciu pojedynczego dysku.
- Opis:
RAID 1składa się z dokładnej kopii (lub lustra) zestawu danych na dwóch lub więcej dyskach. Jest to użyteczne dla tolerancji na błędy. - Korzyści: Zapewnia redundancję; jeśli jeden dysk ulegnie awarii, system może przełączyć się na inny dysk bez utraty danych.
- Wady: Efektywna pojemność przechowywania to tylko połowa całkowitej pojemności dysków, ponieważ wszystkie dane są duplikowane.
- Przypadki użycia: Krytyczne aplikacje, gdzie redundancja danych jest ważniejsza niż efektywność przechowywania, takie jak krytyczne bazy danych.
RAID 5 - Stripping z Parzystością
RAID 5 to typ macierzy łączący bezpieczeństwo z wydajnością i niezawodnością. Poza samymi danymi, przechowywane są także dane o parzystości. Zarówno dane, jak i nadmiarowa informacja są rozmieszczone równomiernie na wszystkich dyskach w macierzy. Szybkość działania całej macierzy RAID 5 ulega zwiększeniu przy dodawaniu kolejnych dysków.
RAID 5 zapisuje dane o parzystości na każdym z dysków według zmiennych zasad. Tak więc informacje pomagające w odzyskiwaniu danych tworzone są bez wielkiego wpływu na transfery. To także pozwala na korzystanie ze wszystkich danych nawet w momencie, gdy brakuje jednego z uszkodzonych dysków; oczywiście dysk trzeba uzupełnić, by “bezawaryjna” macierz była w pełni funkcjonalna.
Minimalna liczba dysków potrzebna do stworzenia tego typu macierzy to 3.
W przypadku awarii jednego z dysków, dane są rekonstruowane poprzez zastąpienie ich danymi z pozostałych dysków i ich sumami kontrolnymi.
Gdy awarii w tym samym czasie ulega więcej niż jeden dysk, wówczas dane z tych dysków zostają utracone.
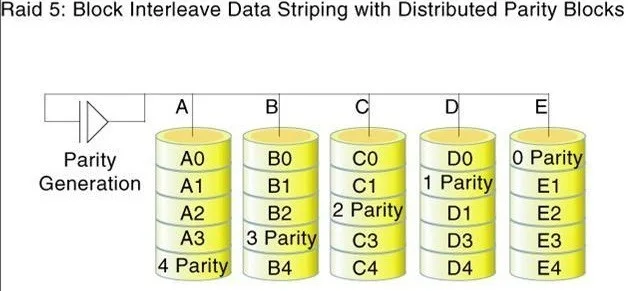
- Opis:
RAID 5łączy trzy lub więcej dysków, rozkładając dane między nimi i przechowując informacje o parzystości na jednym dysku. Informacje o parzystości umożliwiają odzyskanie danych w przypadku awarii dysku. - Korzyści: Dobre równowaga między wydajnością, efektywnością przechowywania a redundancją.
- Wady: Wydajność zapisu może być wolniejsza z powodu obciążenia związanego z obliczaniem parzystości; jeśli dwa dyski ulegną jednocześnie awarii, dane zostaną utracone.
- Przypadki użycia: Serwery ogólnego przeznaczenia, serwery plików i systemy, gdzie pożądane są zarówno wydajność, jak i redundancja.
RAID 6 - Stripping z Podwójną Parzystością
RAID 6 jest porównywalną macierzą z RAID 5, z tą różnicą, że dwa dyski mogą ulec uszkodzeniu równocześnie a dane zostaną odzyskane.
Cztery dyski to minimalne wymagania do zbudowania macierzy RAID6.
- Opis:
RAID 6jest podobny doRAID 5, ale używa dwóch bloków parzystości zamiast jednego. Pozwala to na przetrwanie awarii do dwóch dysków. - Korzyści: Zwiększona tolerancja na błędy w porównaniu z RAID 5.
- Wady: Dodatkowa parzystość powoduje obciążenie, redukując wydajność zapisu i dostępną pojemność.
- Przypadki użycia: Systemy wymagające wyższego poziomu ochrony danych, takie jak krytyczne magazyny danych w środowiskach przedsiębiorstw.
Za pomocą YaSTa można zestawić macierze typu 0, 1 i 5, czyli te, które są możliwe do programowego zdefiniowania.
RAID poziomów 2,3,4 wymagają zestawienia sprzętowego.
RAID 50 (5+0) - Stripping z RAID 5
- Opis: Łączy wiele tablic
RAID 5i rozkłada dane między nimi, efektywnie tworząc tablicęRAID 0z tablicRAID 5. - Korzyści: Oferuje lepszą wydajność i ochronę danych niż pojedynczy RAID 5, może przetrwać wiele awarii dysków.
- Wady: Wymaga co najmniej sześciu dysków; bardziej skomplikowany w zarządzaniu.
- Przypadki użycia: Duże bazy danych, systemy przedsiębiorstwa, gdzie krytyczne są zarówno wysoka wydajność, jak i redundancja danych.
RAID 60 (6+0) - Stripping z RAID 6
- Opis: Podobny do
RAID 50, ale oparty na tablicachRAID 6, zapewniając dwa poziomy parzystości dla każdej tablicyRAID 6. - Korzyści: Jeszcze wyższa ochrona danych niż w
RAID 50, może przetrwać wiele awarii dysków w różnych tablicachRAID 6. - Wady: Wymaga co najmniej ośmiu dysków; ma te same problemy złożoności i zmniejszonej pojemności co
RAID 6, ale spotęgowane. - Przypadki użycia: Systemy przechowywania o dużej pojemności, gdzie integralność danych i tolerancja na błędy są nadrzędne.
RAID 1E - Mirroring + Stripping
- Opis: Hybryda między
RAID 1aRAID 0, która rozkłada dane na trzech lub więcej dyskach w konfiguracji lustrzanej. Oferuje równowagę między wydajnością, efektywnością przechowywania a redundancją. - Korzyści: Lepsze wykorzystanie pojemności dysku niż
RAID 1z podobną redundancją i poprawioną wydajnością. - Wady: Nadal wymaga wykorzystania połowy pojemności przechowywania na redundancję; korzyści wydajnościowe nad
RAID 1są ograniczone przez obciążenie lustrowania. - Przypadki użycia: Nadające się do aplikacji wymagających wydajności, gdzie ochrona danych jest również problemem, ale
RAID 5lub6mogą nie być odpowiednie z powodu ich odpowiednich wad.
Każdy poziom RAID oferuje kompromis między wydajnością, pojemnością i redundancją. Wybór poziomu RAID zależy od konkretnych wymagań aplikacji, w tym od znaczenia integralności danych, wydajności systemu i ograniczeń kosztowych.
Kontroler RAID
Kontroler RAID to specjalizowane urządzenie lub oprogramowanie zarządzające tablicą dysków w celu utworzenia systemu RAID (Redundant Array of Independent Disks). Jego główne role to:
-
Zarządzanie tablicami RAID: Obsługuje konfigurację poziomów RAID (np. RAID 0, RAID 1, RAID 5 itd.), optymalizując redundancję i wydajność w oparciu o wybraną konfigurację RAID.
-
Dystrybucja danych i redundancja: W zależności od poziomu RAID zarządza dystrybucją danych na wielu dyskach, wprowadzając redundancję i parzystość w celu ochrony przed awariami dysków.
-
Optymalizacja wydajności: Może poprawić wydajność, umożliwiając równoległe odczyty/zapisy na wielu dyskach w konfiguracjach takich jak RAID 0, lub poprzez implementację strategii buforowania.
-
Obsługa tolerancji na błędy: W konfiguracjach RAID oferujących redundancję (np. RAID 1, RAID 5, RAID 6) kontroler zarządza procesem odbudowy w przypadku awarii dysku, wykorzystując informacje o redundancji lub parzystości do odzyskania utraconych danych.
-
Kontroler RAID jest komponentem sprzętowym lub warstwą oprogramowania, która zarządza sposobem przechowywania danych na wielu dyskach w konfiguracji RAID, zwiększając redundancję danych, tolerancję na błędy i czasami wydajność. Kontroler RAID abstrahuje złożoność zarządzania RAID od systemu operacyjnego i użytkowników, prezentując tablicę dysków jako pojedynczą logiczną jednostkę dla systemu.
Budowa kontrolera RAID
- Procesor i pamięć: Kontrolery RAID często mają własny procesor i pamięć (pamięć podręczna) do zarządzania tablicą RAID, obsługując zadania takie jak obliczenia parzystości (dla RAID 5 lub RAID 6), co odciąża główny procesor CPU i przyspiesza operacje odczytu/zapisu.
- Interfejsy i porty: Kontrolery RAID są wyposażone w wiele interfejsów do jednoczesnego podłączania kilku dysków. Mogą obsługiwać interfejsy takie jak SATA, SAS lub PCIe, w zależności od typu kontrolera RAID i używanych dysków.
- Format i połączenie: Sprzętowe kontrolery RAID mogą być samodzielnymi kartami, które pasują do gniazda PCIe na płycie głównej, lub zintegrowane z płytą główną. Działają jako pośrednik między dyskami a głównym procesorem komputera.
- Oprogramowanie/firmware do zarządzania: Kontrolery RAID są wyposażone w wbudowane oprogramowanie lub firmware, które dostarcza narzędzi do konfigurowania tablic RAID, monitorowania stanu dysków i zarządzania innymi funkcjami związanymi z systemem RAID.
Typy kontrolerów RAID
Kontrolery RAID różnią się szeroko pod względem swoich możliwości, w tym typów złączy dysków, które obsługują. Te różnice są istotne dla kompatybilności z różnymi napędami dysków i wymagań dotyczących wydajności. Oto przegląd głównych typów złączy dysków, które mogą obsługiwać kontrolery RAID:
SATA (Serial ATA)
- Zastosowanie: Głównie używane do łączenia HDD i SSD w aplikacjach konsumenckich i niektórych przedsiębiorstwach.
- Wydajność: Obsługuje prędkości transferu danych do 6 Gb/s (SATA III).
- Charakterystyka: Złącza SATA są zaprojektowane do bezpośredniego połączenia z pojedynczymi napędami i chociaż mogą być używane w konfiguracjach RAID, są generalnie uważane za wolniejsze niż SAS w konfiguracjach z wieloma dyskami.
SAS (Serial Attached SCSI)
- Zastosowanie: Powszechne w środowiskach przedsiębiorstw do łączenia HDD i SSD.
- Wydajność: Obsługuje wyższe prędkości transferu danych niż SATA, do 12 Gb/s lub 22,5 Gb/s z nowszymi standardami SAS-3 i SAS-4, odpowiednio.
- Charakterystyka: Złącza SAS obsługują wiele napędów na port (konfiguracje punkt-punkt lub rozszerzone), oferując większą elastyczność i skalowalność dla konfiguracji RAID. SAS jest kompatybilny z napędami SATA, co pozwala na mieszanie obu typów w tym samym systemie, ale będą one działać z prędkością najwolniejszego podłączonego napędu.
PCIe (Peripheral Component Interconnect Express)
- Zastosowanie: Używane do bezpośredniego połączenia z płytą główną, szczególnie dla dysków SSD NVMe, które omijają tradycyjne ograniczenia SATA/SAS.
- Wydajność: Oferuje bardzo wysokie prędkości transferu danych, znacznie przewyższające możliwości SATA/SAS, z PCIe 4.0 i 5.0 osiągającymi prędkości do 16 GT/s i 32 GT/s na pasmo, odpowiednio.
- Charakterystyka: Kontrolery RAID oparte na PCIe mogą bezpośrednio łączyć się z napędami NVMe lub używać pasm PCIe do łączenia zewnętrznych obudów. Konfiguracja ta jest szczególnie korzystna dla wysokowydajnych obliczeń, gier i rozwiązań do przechowywania danych przedsiębiorstw.
NVMe (Non-Volatile Memory Express)
- Zastosowanie: Chociaż NVMe jest bardziej protokołem niż typem złącza, kontrolery RAID zaprojektowane dla NVMe wykorzystują interfejs PCIe dla ultra-szybkich dysków SSD.
- Wydajność: Zapewnia najwyższe dostępne prędkości transferu danych dla urządzeń do przechowywania, co czyni je idealnymi dla aplikacji wymagających dużej przepustowości i niskiej latencji.
- Charakterystyka: Konfiguracje RAID NVMe są coraz bardziej powszechne w środowiskach, gdzie prędkość jest kluczowa, takich jak centra danych, wysokowydajne obliczenia i analityka czasu rzeczywistego.
Fibre Channel
- Zastosowanie: Głównie używane w środowiskach SAN (Storage Area Network) do łączenia urządzeń do przechowywania danych na duże odległości.
- Wydajność: Obsługuje prędkości do 16 Gb/s lub wyższe.
- Charakterystyka: Chociaż zazwyczaj nie jest używane bezpośrednio z kontrolerami RAID w samym serwerze, Fibre Channel jest ważne w dużych sieciach przechowywania danych, gdzie konfiguracje RAID są zarządzane na poziomie tablicy przechowywania.
Wybór kontrolera RAID i złączy dysków zależy od konkretnych wymagań systemu przechowywania, w tym wydajności, skalowalności, potrzeb redundancji i budżetu. Wysokiej klasy systemy przechowywania danych przedsiębiorstwa mogą używać kontrolerów RAID opartych na SAS lub NVMe ze względu na ich wydajność i niezawodność, podczas gdy konfiguracje dla konsumentów lub małych firm mogą wybrać kontrolery RAID oparte na SATA ze względu na ich opłacalność i kompatybilność ze standardowymi napędami.